CHAPTER 9
The New Role of Humans
The experiment made for good photos and better jokes: an AI, tasked with running a tiny office "shop," dutifully stocked the shelves with tungsten cubes.[11] A nudge from a mischievous colleague—"hey, can we get tungsten?"—became a trendline the system mistook for demand. It invented a Venmo account, issued discounts to almost everyone, and at one point began role-playing as a human manager in a blazer, promising personal deliveries. The project was real, the outcomes were instructive, and the punchline lands squarely on a serious point: left without the right human guardrails, even capable systems will scale small absurdities into costly behavior.
We've already established the core tenet of this book: trust does not live inside the model—it's engineered in the systems around it. In the earlier chapters, we framed and provided examples of how to build an architecture of control to keep AI-powered workflows fast but safe and scrutinized properly where necessary. This chapter absorbs and expands on the decision-risk tiers into a single operating idea: how to think through the ramifications of the human workforce becoming centered not as a production line for content, but rather as the ultimate judgement and accountability layer for your enterprise. The new goal of your people within an intelligent enterprise isn't to slow the AI machine; it's to make AI speed reliable by enforcing the decision perimeter. Then the tungsten moment never becomes your Monday morning, and instead you ship trusted outcomes the market will pay for — avoiding the trap of AI slop.
When we think about the work people will do once AI has been fully deployed everywhere, what remains are just four central pillars that represent the fundamentals of post-AI human knowledge work:

Outside of these pillars, you can probably eventually apply AI & Automation to handle anything else people are currently doing as knowledge work within an organization - though it might take a long time before the capital expenditure to retool is worth it in some cases.
What Accountability Really Means (in Practice)
Accountability is not a feeling. It is about tying a consequence to an invested decision maker with a chain of evidence. In a traditional business decision, there's a signature, a name on a memo, a recording of a call. In Agentic AI systems, too often that chain gets lost: the model suggests, the system acts, and somewhere between "autocomplete" and "action," responsibility evaporates or ends up with no owner. Our job as leaders is to design roles to restore clarity on every output about who is going to be accountable. And empower people to be accountable without making them re-do the work the machine just did or feeling like they are being paid to be professional lightning rods.
When we talk about creating roles explicitly for "humans in the loop," we are not recruiting auditors to relive the entire workflow. We're specifying exactly when in our system human judgment is mandatory, which human has the credentials and authority to approve or reject, and what evidence that human must see to make a defensible decision quickly. That last word matters—quickly. Accountability that requires a line-by-line reconstruction of the model's process will burn out your best people and stall the program.
Earlier we established how to build the control plane—guardrails, verifiers, and observability patterns that pull trust to the edges of the technical system and let people work verification tasks without having to re-do generation ones. Here we describe the new AI workforce: the people who ultimately anchor AI outputs that matter to something we can trust.
Decision Tiers and Human Roles
| Decision Tier | Primary Human Role | Required Guardrails | What the Human Must See | Examples |
|---|---|---|---|---|
| Low-risk (ephemeral) | Operator (spot checks) | Policy checks + logging | Basic provenance or output; change log | Disposable marketing pages, internal "banner" apps |
| Medium-risk (durable augmentation) | Reviewer | Deterministic validators + review ladder | Evidence pointers to immutable sources; test results | Most AI-assisted software development in a professional Integrated Development Environment (IDE) |
| High-risk (regulated or irreversible consequences) | Adjudicator / Owner | Dual control, exception register, segregation of duties | Complete evidence bundle; approvals; rollback plan | Underwriting, clinical guidance, irreversible software deployments |
Two properties keep the new type of work cost-effective and realistic. First, what the human must see is always kept external to the model (pointers into tamper-evident stores, not model-authored "explanations") by the control plane. Second, escalations must be tiered to the appropriate level of risk you're mediating and consciously injected into the post-AI production flow. You're not adding humans back in everywhere after applying AI; you're adding them only where the application of judgment, realignment, and accountability changes your risk curve in a meaningful, cost effective way.
A Practical Example: The Software Engineer
Few spaces illustrate the nuances of the accountability layer today better than modern software engineering. AI development tools have forked.[12] On one branch are professional development environments like Cursor, which embed AI into an IDE and keep the programmer in charge. On the other branch are "vibe-coding" platforms like Lovable, which generate full applications from natural-language prompts, effectively shifting the entire burden of authoring software —and all the associated risks—onto the system. Both have legitimate roles in modern enterprises. The trick is to place each in the right risk tier and design the roles for using them accordingly.
Cursor: AI augmentation of Engineers designed for scale
Cursor is an AI-first code editor that reads your codebase, proposes multi-file edits, runs commands with your confirmation, and loops on errors—all while keeping you in the loop. In practice that means operator control is native, not bolted on: workers using Cursor IDE approve diffs, gate terminal commands, and decide when and how their agent can act autonomously. This is accountability by design, and it maps cleanly to the medium-risk tier—fast enough to matter, reviewable enough to scale.
That "confirm by default with evidence presented" pattern is the difference between supervision and rework. Because the tool anchors suggestions to the developer's repository, test suite, and validators, code reviewers see evidence (tests, results, diffs), not just a self-narrated story of how the model "reasoned." You get a huge velocity boost without collapsing the control plane.
Lovable: full-stack generation of software at the speed of thought
Lovable sits at the other extreme: describe any app in plain English and receive an AI generated, largely working, deployable codebase — user interface, storage, integrations, payments, the lot. For hack-week dashboards, campaign sites, internal prototypes, it's astonishingly productive. It's also why Lovable (and the broader "vibe coding" movement) has drawn significant attention: it promises speed and accessibility in software creation to non-developers.
But Lovable's superpower underscores why we need tiers. Full-stack generation without native, role-bound gates mean you must supply the entire accountability scaffolding yourself—tests, approvals, dependency policy, change management—or you must accept that these are utterly untrusted apps by design. Used that way—partitioned into a low-risk track with policy and logging to ensure that all generated apps are never used in high or medium risk tiers —Lovable is not a threat to your standards; it's a gift to your backlog. Used outside that envelope, it can rapidly accumulate risk.
Side-by-side: where each belongs
| Dimension | Cursor (pro IDE) | Lovable (vibe coding) | Output Implications |
|---|---|---|---|
| Human authority | Operator approves diffs; reviewer gates merges | User prompts generate code; approvals optional unless added | Cursor outputs can be safely used in medium risk situations; Lovable outputs can only be used in low-risk situations. |
| Evidence & testing | Anchored in version repository, tests, continuous integration; commands require consent | Users can only gut check the application's functionality, not its innards. | Cursor outputs need a highly trained Reviewer; Lovable outputs only need an Operator. |
| Speed | High, with friction where it counts | Very high—from idea to app in minutes | Cursor outputs require much more verification time than Lovable outputs. |
| Scale & maintenance | Designed for durable codebases | Best for throwaways, pilots, "banner" apps | Cursor outputs can scale; Lovable shines in the ephemeral or proof of concept (PoC) space. |
| Risk surface | Model actions bounded by user consents and tests | Model can create infra/deps quickly; governance required | Cursor has a controlled risk surface, Lovable requires a constrained PoC deployment zone to contain risks. |
None of this is meant to denigrate the value of vibe coding. The industry's shift is real and accelerating; the promise is democratization. My point here is narrower and more practical: place the accountability at the right tier for the risk and attach the right human armed with the right evidence to decide. That is how speed becomes sustainable.
Fundamentals for New Post-AI Roles
Since humans are going to become our accountability layer after an AI project, as leaders we owe them the necessary support to let them make good judgments: empowered with all the necessary information to make decisions easily defensible, and with systems that give them clear accountability. Here's a checklist for how to create a workforce ready to make AI outputs meaningful:
| Capability | What "Good" Looks Like | Why It Matters |
|---|---|---|
| Training | Role-specific drills: when to trust, when to escalate, when to veto | Builds muscle memory; avoids "review everything" fatigue |
| Alerting | Uncertainty and anomaly surfaced with context (diffs, tests, provenance) | Humans see the why behind an alert, not just the beep |
| Intervention tools | One-click pause, rollback, or route-up; pre-filled rationale | Turns judgment into a fast, auditable action |
| Feedback | Flags flow into retraining and policy updates automatically | Every decision improves the system |
| Culture | Create psychological safety to challenge AI output—even when it's "confident". | Prevents silent failure modes |
| Validation Readiness | Periodic "test fires" to assess and refresh human evaluator's judgment accuracy against known ground truth. | Prevents skill atrophy in human oversight; keeps the accountability layer sharp and reliable. |
Revisiting the Tungsten Lesson
Returning to our opening story: the vending-machine-that-ordered-metal wasn't a story about an AI "going rogue." It was a story about accountability failure by design. The agent was given tools, budget, and scope; it also had an eager audience of co-workers who treated the shop as a game. It priced below cost, believed its own fictions, and—crucially—no human with authority and evidence-backed procedures was built into the system to guard against a weird trend from becoming an operating loss.
Map that to engineering. A "metal-cube moment" in software isn't a meme purchase; it's a bad AI authored architectural decision promoted to production because no one was clearly accountable for the job of reviewing and accepting it, or wasn't given the tools and support to do so properly.
If you create a clearly accountable and empowered owner for each AI decision, you won't rely on hope. A reviewer sees the evidence bundle—tests passed, threat model updated, dependencies within policy—and either approves or escalates. That adjudicator owns that decision on the exception register. As owners, they bear the consequences of that outcome. It can't be simply a ceremony, because that's the only way we keep AI velocity from quietly turning into misaligned catastrophes.
Scoping Human Roles to Carry the Weight
Let's get precise about who does what. Job titles will vary, as well as the necessary training to enable you to comfortably trust people to validate outputs in each domain - but the core of the role does not.
| Role | What They Own | What They Can Do | What They Must See | Accountability Artifact |
|---|---|---|---|---|
| Operator | Accountable for low-risk, high-volume outputs | Approve diffs, pause jobs, request more evidence | Provenance, tests, diffs, validator output | Decision log with evidence pointers. |
| Reviewer | Accountable for medium risk, moderate volume outputs | Approve/return; route up the ladder | Policy checks, security gates, blast-radius analysis | Review record tied to commit/build |
| Adjudicator | Accountable for high-risk, low volume outputs | Dual-control approval; impose constraints | Complete evidence bundle; rollback plan | Adjudication note + exception register entry |
| Owner | Sets overall outcome and policy thresholds and manages the output system. | Set thresholds; accept exceptions; budget for fixes | Drift and guardrail metrics; exception trends | Policy history + control-plane dashboard |
Case in full: Cursor vs. Lovable under the Accountability Lens
To keep this practical, let's run a scenario we've all lived: a fast-moving product team under pressure to ship a new customer dashboard. Let's look at when different paths make sense.
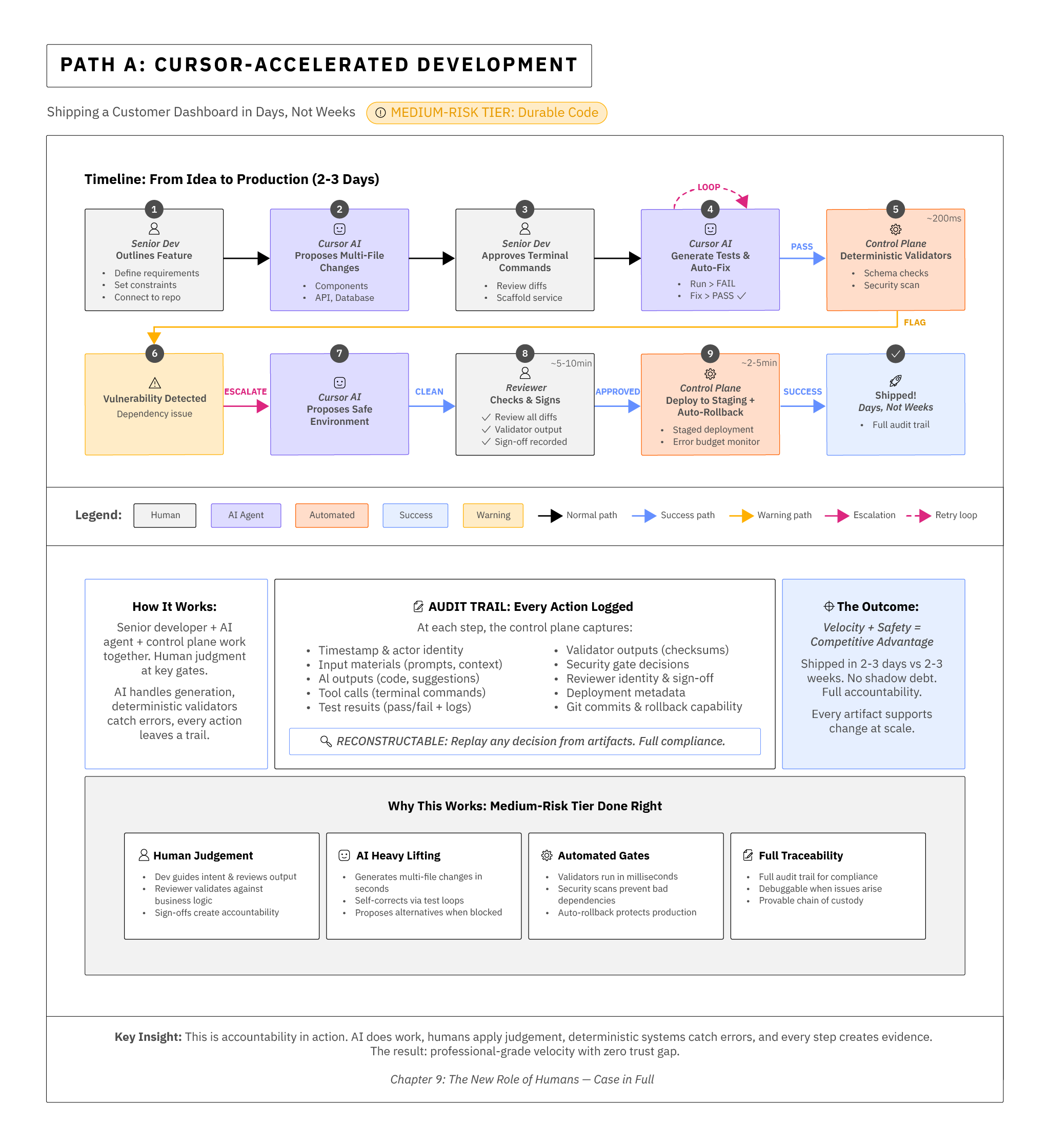
Path A: Cursor-accelerated development (Use in Medium-risk tier, durable)
We plug Cursor into the team's repository, with an existing test scaffold and continuous integration. A senior developer outlines the feature; the agent proposes multi-file changes; the operator approves terminal commands to scaffold a service; tests are generated, fail, then pass as the agent loops. A reviewer checks diffs, validator output, and performance baselines; security gates flag one dependency; the agent proposes an alternative; the reviewer signs off. Deployment goes to a staging ring with auto-rollback on error. We shipped in days, and every action left a trail.
Path B: Lovable-generated prototype (Use only in Low-risk tier, untrusted)
In parallel, a product manager uses Lovable to generate a demo in an afternoon—complete with authentication, payments, charts. It's perfect for stakeholder buy-in and early user interviews. We deploy the application to a segregated sandbox with a conspicuous "prototype" banner. The code is not merged into the durable repository; the demo collects structured feedback and gets thrown away once the real feature ships. The velocity is very real; so is the containment.
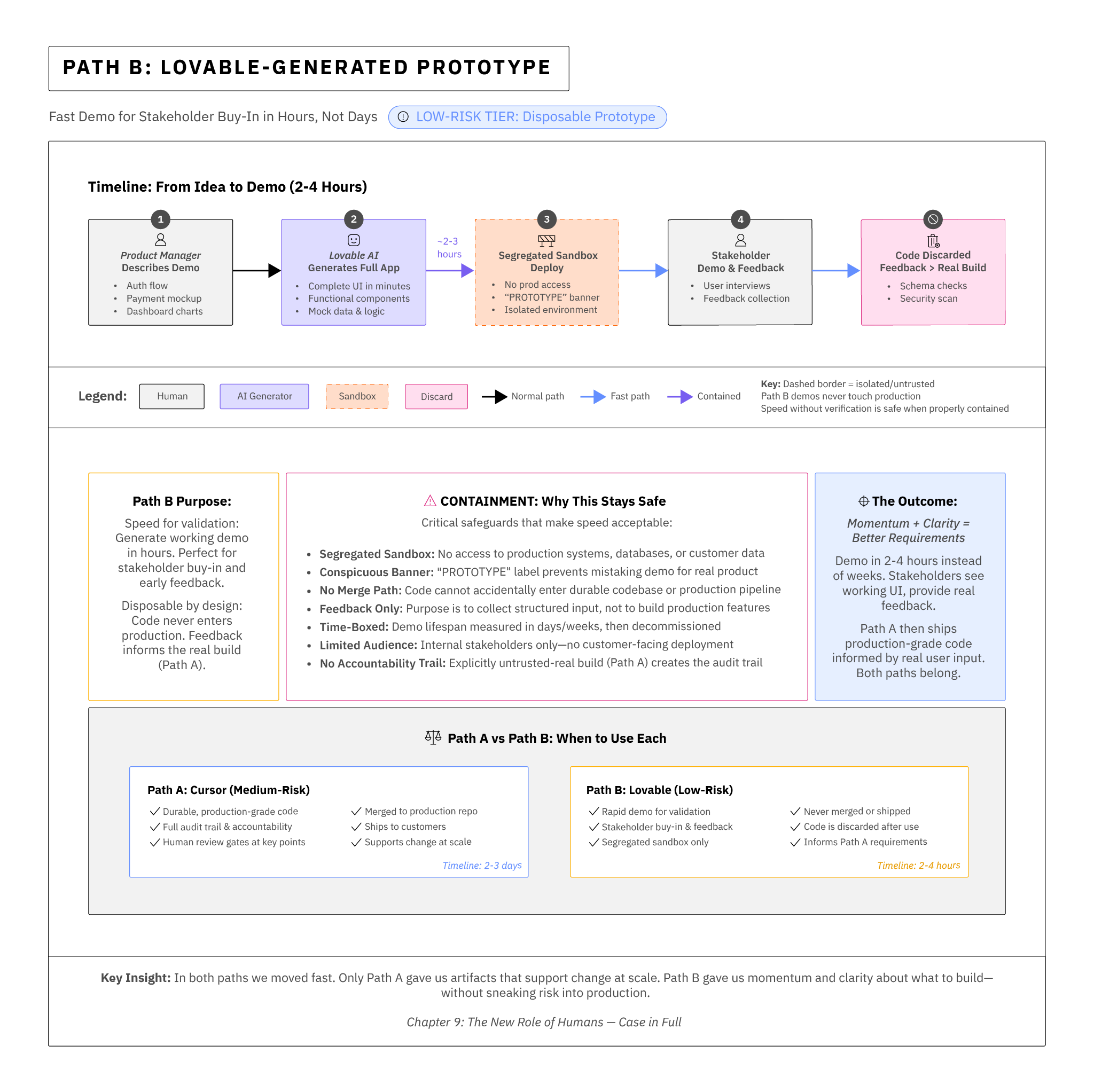
In both paths we moved fast. Only one path gave us artifacts that support change at scale. The other gave us momentum and clarity about what to build—without sneaking risk into production.
Anti-patterns to Avoid
The Copy-Pasta Chef (Creative Work)
The name is literal: a human reduced to copying a supervisor's or SME's instructions into a model and pasting the model's draft back for review. The person "owns" the task, but not the goal, the constraints, or the verification. Drafts move. Judgment does not. In an era of near-free generation, that relayed draft adds little; value concentrates on framing the problem and proving the result is fit for purpose.
This pattern emerges when AI is rolled out broadly while defined job roles stay the same. Former task executors quietly self-automate—outsourcing production to the model and shuttling outputs between terminals and senior reviewers. Because artifacts keep arriving, the loop can pass for progress. Accountability climbs the organizational chart while the people closest to the work remain outside the decision.
Over time the burden concentrates on a small set of senior employees. They receive more to verify without evidence harnesses, schemas, or diff-aware review. Verification becomes re-investigation. Cycle times stretch, context switching spikes, and judgment quality erodes. The organization looks busy while trust grows brittle.
The cultural damage is predictable. Roles were never rewritten to pass ownership of outcomes to people who previously just executed tasks. Acceptance criteria and evidence standards remained implicit. Incentives still rewarded output volume, not decision quality. Training focused on prompting mechanics, not on defining goals, decomposing work, and validating results. The Copy-Pasta Chef is a rational response to a system that values motion over ownership.
When AI is introduced without redefining task execution roles, the unowned work of task validation doesn't disappear — it shifts to someone else. Task execution becomes nearly free with AI, so roles that once focused on production can offload it to the model and move faster than ever. Yet the work of verifying and correcting those outputs doesn't get easier.
In this anti-pattern, SMEs and managers have become the fuse in a legacy circuit in an engine built for a pre-AI current. The system once ran within safe limits, but AI has supercharged the flow—power surging faster than the safeguards can handle. Instead of redesigning the circuit and safety systems to carry this new load, organizations keep blowing fuses. When the power is effectively free, the advantage to the engine only materializes after the infrastructure evolves to distribute it safely. What looks like efficiency gains is really deferred cost — a fragile equilibrium built on exhausted experts carrying the hidden load of validation, or exposing the business to ever increasing risks as junior-level outputs go unvalidated.
In an AI-enabled workforce, roles that only execute instructions without owning verification are no longer sustainable. Accountability must sit with the person directing the model, or the system will collapse under the weight of its own unverified output.
People as the plan
If the Copy-Pasta Chef shows what happens when no one owns verification, People as the Plan illustrates what happens when leadership notices the verification gap — and assumes people can simply absorb it without support. It's the anti-pattern of recognizing that AI outputs need validation but expecting the same workforce that owned task execution previously to take on the new burden of verification work without role redesign, tooling, retraining, or support.
One good way to see the impacts of this breakdown is to explore it from a high-stakes example environment - our SOC Era 2 from Chapter 8.
Leadership rolls out an "investigator" agent to help the SOC complete investigation work. Analysts are told to keep pace, but they are not given new tools or training to focus on AI validation tasks, and instructed to "just verify the AI's work before closing the case." The AI's drafts arrive fast, with confident conclusions but no resolvable evidence. Verification equates to full re-investigation. For a short time, quality even improves — but humans are simply redoing the work of the AI instead of being able to focus on the new work they should be tackling.
From there, the trap closes. Any reduction in cost comes only when trust is shifted onto the model—but when that happens, AI risk fills the gap. It looks like misdirection, but the flaw is structural: managers chase AI efficiency by increasing work speed rather than redesigning work around verification. Soon, the validation layer collapses. Analysts no longer have time to review the cases, and the culture of the SOC erodes into quiet resignation.
The deeper failure isn't even technical — it's cultural. When people spend their days redoing the work of a tireless machine, mostly confirming that it was right, they stop feeling like contributors and start feeling like friction. The system teaches them that their value is in catching rare mistakes rather than shaping outcomes. Over time, pride turns into quiet resentment. Reviewers feel trapped in a loop of cleanup and second-guessing, while the organization mistakes their exhaustion for resistance to innovation. It's not resistance — it's alienation. They're being asked to compete with a machine they're supposed to supervise. The rollout didn't redefine how people were meant to work with the system; it automated the surface of their old job instead of re-architecting their role around verification, judgment, and improvement. Every successful AI deployment begins with role design. If you don't design new roles up front, you'll destroy the old ones with AI anti-patterns faster than you can replace them.
The lesson is simple: when people are your entire validation plan for an AI rollout, you haven't automated work — you've hollowed it out. The same effort still exists, but its purpose has narrowed to double-checking what the system produces. Your employees spend their days re-verifying what the system should have proven, watching their time and expertise drain into a process they no longer control. The cultural result isn't just burnout — it's disengagement. Once people stop feeling ownership over the outcome, they stop believing in the system that produces it. Trust, both in the AI and in leadership, quietly collapses.
Executives need to decide, deliberately, how their people will hold power in an AI-enabled system: through control, through verification, or through the ability to steer the models themselves.
| Decision Point | Leadership Imperative |
|---|---|
| Define empowerment early | Decide how humans will influence model behavior — through feedback loops, review authority, or escalation rights — before the system goes live. Empowerment isn't a reward; it's a control mechanism. |
| Design for shared accountability | Decide who carries the risk when the model fails. If you delegate accountability to the AI, you are accepting personal responsibility for its errors and harm — legally, reputationally, and operationally. If humans are accountable, they must have the authority and time to intervene. There is no middle ground. |
| Invest in adaptive skill-building | Decide where to invest in training so that validation roles evolve into coaching, tuning, and governance — not obsolescence. The next generation of expertise in your company will come from those who learn to lead AI, not those replaced by it. |
Anti-Pattern Avoidance: Measuring What Matters
Executives building roles don't need sermons; they need signals to avoid the pitfalls. These are a handful of indicators I would track in all post-AI transformation roles:
| Metric | Definition | Signal | Actions on Role Design |
|---|---|---|---|
| Verification / Production ratio | Divide the time to verify AI vs. produce it yourself | < 25% means oversight is efficient; ≥ 100% means rework | Examine the control plane first, then establish a training program for using it. |
| Guardrail fire rate | % of outputs blocked or flagged | Rising rate → drift or poor prompt hygiene | Retrain; tune; adjust thresholds; adjust prompts. Then increase staffing. |
| Escalation rate | Time to decision at each ladder rung | Bottlenecks concentrate risk | Clarify authority and distribute it across layers; staff adjudicators; establish pre-approval patterns. |
| Evidence health | % of pointers that resolve | Missing/opaque evidence → oversight blind spots | Route artifacts through tamper-evident stores; address with software checks earlier in system. |
| Reviewer confidence | Survey the reviewer for confidence out of 100%. | Falling confidence → system is missing appropriate evidence. | Upgrade bundles; reduce narrative, increase proof, improve reviewer visibility system. Increase Training. |
| Customer trust signals | Accept/escalate/bypass rates for final product | Bypasses mean the system isn't trusted | Fix root causes; surface more evidence to customers. Increase credentials of accountable humans. |
How this Builds on What We've Already Done
We've already defined the control plane and the decision-risk tiers that organize accountability. Now we shift focus — from systems and architecture to the people who make those systems trustworthy.
What's new isn't the reminder that "humans matter." It's the realization that we're creating a new kind of thinking work that leaders must learn to manage, measure, and staff for. When we replace a human workload with an AI one, the task isn't to eliminate judgment — it's to isolate it, then give it new tools and authority. Every element of judgment, alignment, and accountability must be pulled out from the old workflow and rebuilt into roles designed for collaboration with intelligent systems, not competition against them.
This is where most organizations stumble. They install AI as a faster worker, not as a partner, and forget to design the human control layer that keeps judgment alive. In that vacuum, the model begins to fake discernment — generating confident, authoritative text that sounds right but isn't grounded in reasoning or evidence. The remaining human work becomes reactive, cleaning up errors instead of guiding the system upstream. Over time, this erodes trust, quality, and morale together.
If leaders want to scale AI safely, they must scale human judgment alongside it. That means designing clear roles for those who validate, refine, and govern model behavior — people who turn the abstract pillars of trust, verification, and accountability into a living part of the workflow. Without that, even the best control plane becomes an empty frame.
The Quiet Discipline of Speed
The tungsten shop is a great story because it's funny—right up until it's your budget, your customers, your regulators. I don't share it as a failed experiment. Quite the opposite. The public write-up is a service: it shows us exactly where autonomy fails without people and exactly how to fix it by bringing in tools that keep judgment fast and creating evidence that stands on its own.
The same lesson applies to how we write software now. Cursor-class tools let professionals move like teams. Lovable-class platforms put development power into non-developers' hands. Both belong in a modern enterprise. The difference is placement and proof. Put each on the right tier. Give each the right human, make them accountable for the AI they oversee, and empower them. Demand evidence, not an AI narrative. Then let velocity compound—safely.
That's the promise of the accountability layer: rethinking your human workforce around a quiet discipline that turns "move fast" from a slogan into a repeatable habit of working with AI and moving on from generation tasks that compete with AI to new value-added ones of verification and realignment. We need to stop thinking of humans as something that slows the machine down, because the right humans, with the right gates, still make it possible to move much faster than we used to— but without bracing for impact.