CHAPTER 7
Revisiting Trust
Some Principles for Restoring Confidence in AI Decisions
On a Tuesday afternoon, a junior lawyer caught a critical AI error. The firm's new legal assistant had drafted an immaculate brief with citations dense enough to make a judge nod, but then a paralegal chasing down one reference hit a dead link. Then another. Two cited "cases" didn't exist. The problem wasn't really the AI hallucination. It was the architectural failure to safeguard and verify trust that had been placed in a model. The legal team centered trust for a critical output on a model and left the rest of their case prep system with nothing to say for itself.
Trust in AI isn't about slowly educating users to trust the models; it's a conscious design choice to create systems that allow everyone to easily inspect and validate every black-box decision that comes from the model. When leaders say, "we need our customers, regulators, and our own people to trust the output," what they really mean is "we need to create a system that makes AI decisions visible and verifiable — the system must perform well even when the model it's built around is compromised." If we build that system of verification well, we create new verification work, but that work remains far cheaper than the generation work the AI took away. Done well, gains from AI remain enormous and well worth the investment. But if we fail at that verification system, we're either exposed to a set of unknown and expanding risks from AI or we force humans to simply repeat the tasks AI automated to verify we can trust it. That is not augmentation; it's just redundancy dressed up in new tooling.
This chapter delves deep on the how. How can you go about designing AI embedded software systems to enforce model transparency, explainability, and alignment. If you do this, the trust of your business is placed where it belongs — not resting on the black box, but rather in guardrails that surround it and ultimately in the hands of the humans who are accountable for its output. An emerging novel type of knowledge work – verification work – becomes necessary for handling the inescapable edge cases and unpredictable outcomes that come with using non-deterministic models as a powerful new part of your software stack.
We'll ground these ideas in scenarios (starting with that legal assistant), and we'll set up the next chapters: the Architecture of Control (how oversight actually works at scale), the art of leveraging humans in an accountability layer (figuring out who carries the responsibility and when), and evaluating decision-risk tiers & review ladders (how we right-size to get the control we need without sacrificing speed).
Humans earn trust through credentials, accountability, and consistent character; AI demonstrates how you can trust each output through verification systems. Models in the end remain opaque, probabilistic, attackable, and subject to influence from the data they process — and portions of that data are often something an attacker can control. The move that changes adoption curves for AI systems from failure to success is simple to say and rigorously difficult to implement:
Let AI do work; but move trust off the AI outputs and rest it on guardrails and people.
In practice, this means creating a complementary non-AI system for each AI that accomplishes three things at every single model call:
1: Create Transparency — What did the AI look at? What did it do?
| Principle | Description |
|---|---|
| Evidence out of band | All evidence references should be created by the system, not the model. Supporting material should reside outside the AI's output loop and be referenced by the AI only as immutable pointers into sources the model cannot alter. |
| Visible deterministic verification first | All evidence cited by the AI must first be validated by non-AI systems that deterministically confirm existence, relevance, and integrity before reaching human reviewers. These checks should appear as distinct, visible confirmations separate from the AI's narrative. Any failed verification should force the model to reattempt or flag the issue before human review. |
2: Achieve Explainability — How did AI justify each step or action?
| Principle | Description |
|---|---|
| Explainability without self-authorship | Keep the AI's reasoning separate from the system's record of actions and evidence. Explanations should be reconstructed from verified system traces that show what the AI accessed, how it filtered information, and why certain data was selected. The model's narrative appears alongside — but never replaces — these independently validated traces, allowing humans to assess whether the reasoning truly follows from the evidence. |
3: Alignment — Was the AI's output correct and what we wanted, or not?
| Principle | Description |
|---|---|
| Human in the right loop | Design interfaces so that humans can see the system's evidence, confidence, and reasoning context — and intervene proportionally to the level of uncertainty or decision risk. Escalation paths should be explicit and tiered. |
| Alignment guardrails | Constrain what the AI can access and require that every assertion or decision be backed by verified evidence. If an output cannot be validated, it should remain visibly incomplete or non-actionable until reviewed. |
| Audit everything | Record every input, retrieval, decision, and override in an immutable log. Auditable lineage — not model confidence — is what sustains trust over time. |
A common failure pattern I see is engineers treating "explainability" as just another prompt. They run the model once to make a decision, then call it again with a prompt to explain what it just did. That second answer feels satisfying — but it's built on the same unverified reasoning as the first.
True explainability can't be authored by the model. It must come from the system around it: from logs, traces, and verifiable references doing fact-checks the model can't control. You don't ask a junior analyst to grade their own exam. Don't ask a model to verify itself.
Scenario: Rebuilding Our AI Legal Assistant for Trust
As an exercise, let's try to redesign the AI tool that burned the legal team so they can trust it again. We'll call out good principles and describe what they would look like so we can contrast with a good system.
The Original Failure Case:
The AI model generated a case brief and then also generated friendly, plausible citations. The system gave no guarantee that those citations mapped to anything real, and the system did not support case reviewers with a fast path to verify and fact check the work. In essence, the system trusted and shipped just AI outputs. But it failed to do anything to establish trust in that output or help humans to do so. When the error was caught, overall faith in the entire system suffered dramatically, created severe reputational consequences for the firm, and scuttled the AI project's adoption as a failure.
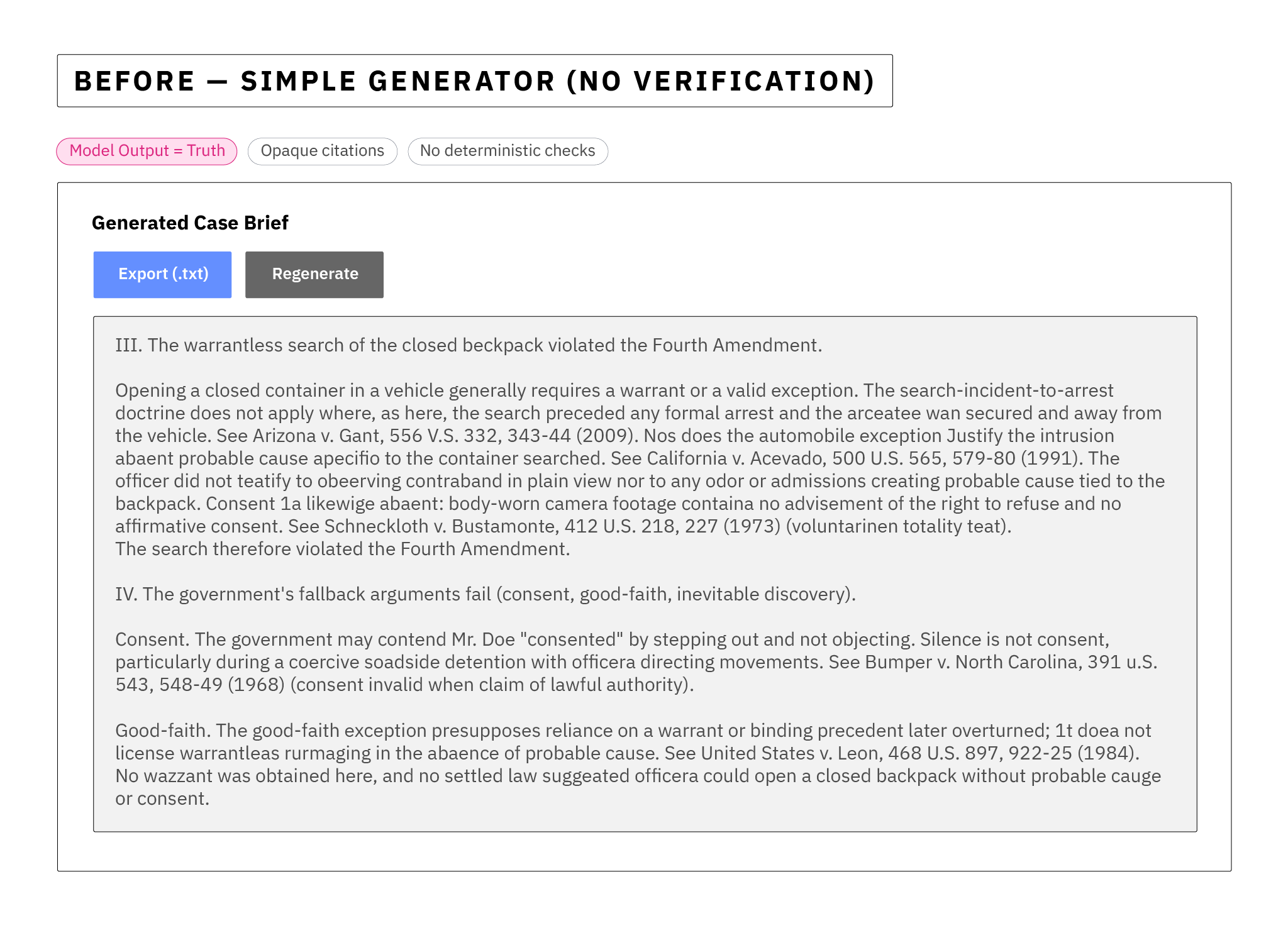
A Trustworthy AI in the Same Situation:
| Principle | Description |
|---|---|
| Evidence out of band | We'll make it so the model is incapable of pasting "supporting quotes" or crafting its own text into the chain of evidence when generating narratives. Instead, it can only reference and output pointers — IDs and permalinks — to a read-only case law corpus, locked behind an API it cannot write to. |
| Deterministic verification first | A non-AI service validates every cited pointer: existence, jurisdiction, date, relevance threshold (e.g., shared key terms and holdings), and basic Shepardizing (i.e., a citator check for whether a case is still "good law") signals (overruled, negative treatment). The result is rendered as green/yellow/red markers inline with the draft in a new UI designed expressly for the human work of verification that is replacing the human work of generating the brief. |
| Explainability without self-authorship | A new UI for paralegals now shows a machine-generated reasoning map that is not sourced from the model's narrative. It's reconstructed from the deterministic pipeline: which statutes and precedents were fetched, which were selected, what features matched (issues, parties, holdings), and how the selection thresholds were met. |
| Alignment guardrails | Prompt inputs are sanitized; retrieval scopes the AI can access are constrained by matter, jurisdiction, and date; citations are required for every legal assertion. If a claim cannot be supported by a verified pointer, it renders as a grey box that cannot be copy-pasted without acknowledgement. |
| Human in the right loop | Secretaries and lawyers see (a) the draft, (b) the verification markers, and (c) one-click deep links to the authoritative text. Edge cases (e.g., yellow markers for borderline relevance) trigger review ladders — paralegal → associate → partner — that are formalized in Decision-Risk Tiers. |
| Audit everything | Every step — prompts, retrievals, verification results, overrides — lands in an append-only log. We can show a regulator, a court, or a client exactly how we arrived where we arrived. |

The model still accelerates the work of drafting a case brief by an order of magnitude but trust no longer lives or dies inside the black box of a model. It lives in the evidence store, the deterministic checks, the review ladder, and the audit trail. Lawyers don't have to do the case prep work; they can verify the AI work with confidence much faster than they could produce it by hand. If the AI throws an error, it generates a bit of work, but now humans are able to trust the overall system because they understand where failures occur and what is there to catch them. Trust is moved back to a human validator, not left on an inscrutable model, but with a much cheaper work process than the original.
What we just walked through wasn’t unique to the legal field. It’s what the three pillars of trust — Transparency, Explainability, and Alignment — look like when they’re forced to stand up under pressure.
Earlier, we introduced those pillars briefly, almost as definitions. The scenario showed how they behave when stakes are real — when an organization has to rebuild confidence, not by claiming its AI is smarter, but by showing publicly how their employees are held accountable for their verification work.
Now, we’ll go deeper. Each pillar deserves its own blueprint: the specific design choices that make it visible in production systems, measurable in operations, and comprehensible to everyone who has to live with the results. These are not abstractions; they’re implementation patterns. And if the case study was the story of a single rebuilt system, what follows is the architecture any trustworthy AI system can be built upon.
The Three Pillars, Operationalized
From principle to practice: turning trust into system design.
What worked in the legal assistant wasn't luck, and it wasn't artistry. It was structure. Every safeguard that restored confidence in that system mapped back to one of three foundational pillars: Transparency, Explainability, and Alignment. Together, they form a repeatable architecture for governing intelligent systems under real-world pressure — where accountability, not AI, defines trustworthiness.
These pillars aren't values. They're control surfaces. They don't make a model "good"; they make its specific outputs provable. Each ensures that even when the AI fails — or is actively subverted — the overall system still behaves predictably, audibly, and within human-defined boundaries.
Transparency
Principles: Evidence out of band; Visible deterministic verification first
Transparency isn't about asking an AI to explain itself; it's about giving humans direct visibility into what it actually did. In engineering terms, transparency is a bill of materials for decision-making: what data sources were touched, what transformations occurred, which policies were active, and who or what changed the output. Internally, it's observability. Externally, it's comprehensible provenance.
Design choices that create transparency
| Pattern | Description |
|---|---|
| Immutable pointers, not generated evidence | The system — not the model — generates all evidence references. Each pointer includes IDs, timestamps, hashes, and source links into repositories the model cannot alter. |
| Retrieval manifests | Every retrieval-augmented answer includes a manifest of what was fetched, what was selected, and under what constraints. |
| Policy overlays | Expose which policies gated or influenced the model's behavior — e.g., "No personal data," "EU corpus only," "confidence ≥ 0.8." |
| Change logs | Attribute every revision, override, and deletion. When evidence changes, the who, what, and why must follow it. |
Explainability
Principle: Explainability without self-authorship
Explainability done wrong is a bedtime story — a comforting narrative the AI invents after the fact. Done right, it's a testable reconstruction of how features, rules, and evidence produced a specific outcome. It's not prose; it's provenance you can query.
Design choices that create explainability
| Pattern | Description |
|---|---|
| Reasoning maps from deterministic pipelines | Build explanations directly from system activity: retrievals, scoring functions, rule evaluations, and applied constraints — not from generated text. |
| Confidence with context | Pair each confidence score with its justification: why it's high, which features matched, and what conflicts were detected. |
| Edge highlighting | Flag where the model extrapolates beyond verified evidence and offer structured review actions — "request more sources," "narrow scope," "clarify term." |
| User-level clarity | Design explanations that any stakeholder — engineer, executive, or regulator — can follow without translation. Accountability should never depend on technical fluency. |
Explainability exists to make reasoning disprovable. It ensures that when an AI's logic breaks, the failure is visible early — and can be corrected before it compounds into risk.
Alignment
Principles: Human in the right loop; Alignment guardrails; Audit everything
Alignment, in real systems, isn't about moral calibration. It's about containment. The question isn't whether the model "shares your values," but whether the surrounding system ensures that — even if it's compromised — outcomes still land inside ethical, legal, and business boundaries.
Design choices that create alignment
| Pattern | Description |
|---|---|
| Constrained interfaces | Give the model only the tools, scopes, and data paths it needs — nothing more. The narrower the interface, the smaller the blast radius. |
| Adversarial sanity checks | Run deterministic filters for known bad patterns — prompt injections, data exfiltration attempts, jailbreak signatures — before model invocation. |
| Result gating | Require dual control for high-impact actions. No model should unilaterally recommend or execute where human or policy review is mandated. |
| Drift watch | Monitor for distribution shifts in inputs and outputs, and escalate when behavior veers. Alignment that isn't watched becomes misalignment by default. |
Systemic alignment isn't cheap — but it's predictable and reliable. At scale, the cost of verifying your outputs is almost always lower than the cost of remediating all the breaches and failures from trust wrongly placed on a model. Systems of verification, containment, and human oversight are what let AI operate safely at enterprise scale.
The Cost of Trust is the Price of Scale
Transparency, explainability, and alignment form the operational spine of trustworthy AI. They don't slow progress — they make progress sustainable. Without them, every deployment is a bespoke experiment; with them, trust becomes a system feature you can audit, replicate, and scale.
What follows in the next sections is how trust becomes visible beyond the engineering environment — in the interfaces that show verified work to customers, and in the economics that justify its cost. Because building systems that can be trusted is only half the battle. The other half is proving that trust was earned.
Internal and External Trust — The Same Mechanics, Different UI
Internal trust is leadership confidence: Can my team rely on this tool without opening us to regulatory, financial, or brand risk? External trust is the customer-facing equivalent: Have I, as a patient, client, or citizen, been given compelling reason to accept what this AI-assisted system is telling me?
The mechanics to create it are the same — pointers, checks, reviews, audit — but the presentation changes. Here's a quick example of how our reworked legal case brief AI system might showcase why the output can be trusted even though AI generated it:
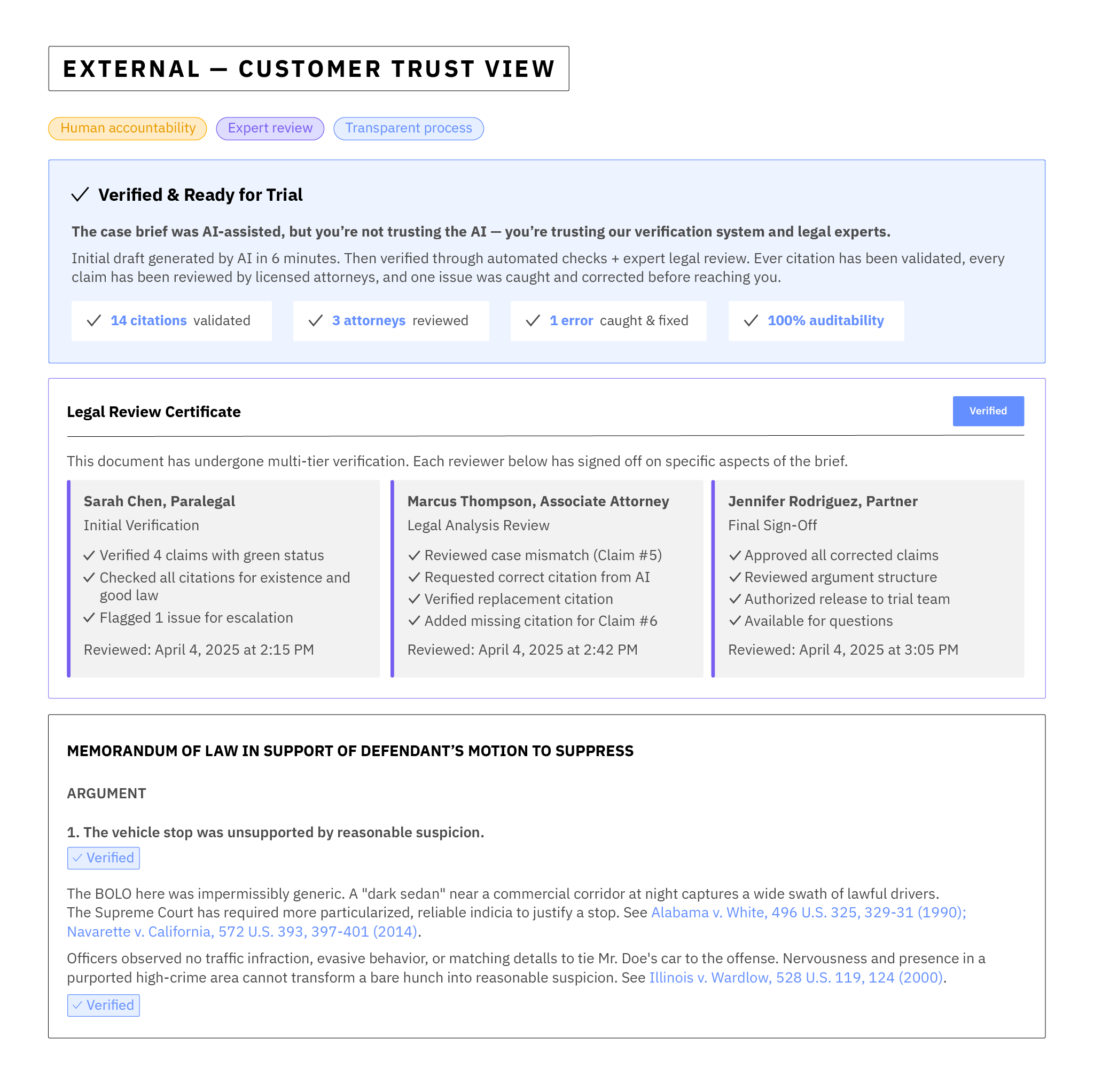
When you properly build trust into the system, you don't have to mint separate "trust" for each audience. You simply derive different views that allow different audiences to understand why they can trust what you've produced. In our example, the customer trusts the firm – because they can see how the firm passed trust from the AI on up to the partner before asking them to trust the firm.
We can easily see how other similar systems might be built following the architecture and patterns we've discussed so far in this chapter. Here are a few examples:
Finance scenario: A portfolio tool recommends rebalancing. Internally, the desk lead sees the retrieval manifest (market data snapshots at a specific time, macro signals used, compliance constraints applied) and signs off with a documented rationale. Externally, the client sees the simplified explanation, the time-stamped data references, and the advisory's credentialed sign-off. The same rails; two views of trust.
Healthcare scenario: A diagnostic assistant suggests a treatment path. Clinicians get alignment guardrails (approved protocols, contraindication checks, confidence bands) and one-click literature pointers stored in a validated repository. Patients get the accessible version: what factors mattered, what risks were considered, and assurance that a licensed clinician reviewed the recommendation.
The Economics of Trust: Verification is the Value of an Enterprise
The table distills the essentials. If it's already clear, skip to the tools; if not, the next section unpacks the why and how.
| Executive takeaway | Why it matters | What to do |
|---|---|---|
| Creation has commoditized; the value of knowledge work now concentrates in verification. | When AI can generate endless content, the value of anything not verified collapses. In a market where supply is effectively infinite, only things buyers can trust retain worth. | Invest in verification systems and visible provenance to anchor value on what's scarce: verification by accountable experts. |
| Verification capacity is your growth bottleneck. | Revenue and risk scale proportionately to what you can credibly sign off on. | Trust scales only as fast as verification does—set performance targets for review and validation before increasing what your AIs produce. |
| Your product is now the assurance of correct outcomes, not artifacts. | Differentiation shifts to auditable processes tied to accountable humans. | Name, price, and market your verification layer as part of your offer. |
| Instrument provenance and accountable sign-off. | Shortens sales cycles, eases audits, and reduces rework. | Log sources, tests, reviewers; expose customer-facing attestations. |
| Unverified volume ("AI slop") is a balance-sheet risk. | Erodes brand equity and creates potential liabilities. | Throttle generation to verified capacity; set discard policies for unverified output, and don't put your reputation behind it. |
The Core Formula
The Economics of Trust is about recognizing that in an age when AI can generate content, code, and decisions at near-zero marginal cost, the real value shifts to what can be proven. Verification is no longer overhead—it's the control point that converts free generation into reliable outcomes. Because validation has a measurable cost and a quantifiable benefit, especially when error rates are uncertain, it becomes not a drag on innovation but the mechanism that turns generation velocity into actual value.
At its simplest, verification becomes economically justified when:
Cv < Pe×Le
Where:
| Variable | Definition |
|---|---|
| Pe | Probability of a high-impact AI output error without verification |
| Le | Mean loss when an unchecked output causes downstream damage |
| Cv | Average cost to verify a decision (human review + tooling) |
Verification pays for itself when the cost of checking an AI's output and validating it is less than the expected loss from letting an unchecked error slip through.
Before AI, creation and verification were welded together. Producing anything that mattered—an audit memo, a quarterly plan, a design review—required time, skill, and judgment. The effort itself served as a quiet certificate of authenticity. When a human put their name on something, the labor behind it implied context, intent, and accountability. In that world, you couldn't cheaply create without also doing some measure of verification along the way, and some human somewhere was always accountable for everything created.
AI broke that linkage. The cost of creation fell toward zero, and with it the natural verification that human effort used to bake into the work. For the first time, it became easy to generate something you didn't fully understand.
We see the consequences everywhere. The internet is awash in what many now call AI slop: eBooks spat out overnight with prompt text left mid-paragraph; corporate posts stitched from plausible clichés; outbound messages written for no one in particular. This isn't just a quality problem—it's an economic signal. When creation becomes infinite and unfiltered, outputs lose value due to the law of supply and demand. They accumulate like inventory no one will buy.
That's the core inversion leaders need to internalize: verification is now the only part of creation that represents durable value. Generation is abundant; belief is scarce. The differentiator isn't how much you can produce—it's how reliably you can prove that what you've produced can be trusted.
This does not diminish the enterprise; it explains why enterprises still exist. If verification didn't matter, most firms would be optional. An accounting practice could reduce to an API that reconciles ledgers. A law office could collapse into a contract-drafting endpoint. But organizations endure because markets do not run on creation—they run on belief in correctness. Customers are really buying the confidence that qualified people, operating inside a designed system, have validated the result and will stand behind it.
Consider accounting. The value was never in typing numbers; it was in ensuring the numbers could withstand scrutiny. AI now drafts reconciliations, summarizes footnotes, and flags anomalies at a pace no team could match. That doesn't erase the accountant; it amplifies them. One professional can now supervise and validate the AI generated outputs that previously took many professionals. The verification layer becomes a force multiplier on expertise, not a replacement for it. It's where the enterprise now earns its margin.
This is where the earlier theme in this book returns with sharper edges. I wrote that the cost of trust is the price of scale—businesses grow only as fast as their systems of verification allow. What we're seeing today isn't a reversal; it's an evolution. As creation becomes effectively infinite, verification becomes the constraint that defines value. Scale no longer depends on how much we can produce, but on how much of what we produce can be trusted.
For executives, that shift has immediate operational implications:
| Principle | Description |
|---|---|
| Treat verification as a product, not a compliance chore. | Customers are buying the credibility of your process as much as the output itself. Design it, name it, and price it as part of the value you deliver. |
| Move from artisanal review to systems of review. | Human judgment still anchors trust, but throughput comes from well-architected pipelines—capture provenance, automate what can be automated, and make human sign-off legible. |
| Measure trust like a capacity. | If your workflow's creation rate is 10× higher than its verification rate, you're building inventory no market will value. Increase verification capacity first; creation will take care of itself. |
The temptation in this moment is to celebrate speed and volume because the demos look impressive. That is the wrong metric. Speed without verification creates liabilities: brand erosion, customer churn, and regulatory exposure. All of them move faster than revenue. In contrast, a visible, believable verification process compounds trust. It shortens sales cycles, reduces rework, and turns audits from episodic pain into an ongoing advantage.
This is also why "AI slop" is a strategic warning, not just an aesthetic irritation. It's what happens when organizations let creation engines run without a verification engine attached. Internally, it clogs channels with content no one uses. Externally, it trains customers to discount your words. In both cases, it erodes the market value of what you sell. When customers stop trusting your outputs, it doesn't just cheapen your message—it cheapens your business.
The remedy is straightforward, even if it requires discipline: make verification the control surface of the business. Capture how each answer was produced. Log what was checked and by whom. Separate what a model suggested from what the organization backed. Give people a fast path to escalate doubt. Then expose that machinery, thoughtfully, to customers and regulators. When the process is transparent and credible, the output regains value.
None of this argues for nostalgia. We are not going back to the era where effort alone proved quality. We are moving forward to an era where designed verification—human accountability, instrumented pipelines, visible provenance—does the proving. In that world, AI's abundance doesn't drown the enterprise; it powers it. Creation becomes the raw material. Verification is the factory floor.
The conclusion is simple enough to carry into any boardroom: when creation became free, trust and reliability of outcome became the product. Your competitive advantage is no longer how quickly you can generate, but how convincingly you can verify. Build for that, and the flood becomes a reservoir. Ignore it, and you'll be swept into the same undifferentiated current as everyone else.
Practical Tools to Ensure Confidence in AI Decisions
We've just made the case that verification is the product; now we'll make it operational in three passes: spot what unravels trust, orient scope and risk, then wire verification into the workflow.
Here's the turn from argument to action. If the last section made the case—that creation is abundant, and value now lives in verification—this one gives you the field kit to run with it. We'll introduce three tools, each for a different job: the Anti-patterns to spot what quietly unwinds trust in AI projects, a Simple Map for Leaders to assess scope and risk before you scale, and a Checklist for Trust by Design to ensure you have wired verification outside the model with visible provenance and accountable humans. Follow them as gates, not guidance: they will give you evidence over assertion, capacity before creation, and help you make sure you don't scale an AI project faster than you can prove the outputs can be trusted.
Anti-Patterns that kill Trust in AI Outputs
Pre-flight checks for AI projects: These quiet failure modes look productive but erode verification and provenance. If one shows up, pause generation and raise verification capacity first.
If any row fits, don't scale output—scale proof.
| Anti-pattern (plain name) | Why it's so common | 30-second test (what you look for) | What it turns into if you ignore it | One move that fixes most of it |
|---|---|---|---|---|
| Demo-only validation | Teams ship to the deadline; test data is clean because the pilot was clean. Low-prevalence hostile edge cases are dropped to focus on the behaviour during the majority of successes. | Open the test set: do you see examples of how the system handles hostile or wrong AI outputs and edge cases? If not, this anti-pattern is present. | Public "how did that slip through?" failures; credibility shocks; expensive rework, loss of trust. | Make handling edge/adversarial test suites a release-blocking criteria for AI projects; carefully inspect what happens when the AI is wrong. |
| Same-path proof | Tooling defaults make it trivial for the same path to "explain" itself; provenance capture is extra work. | Ask for the proof path: is evidence (sources, tests, checks) produced by a separate mechanism from generation? If "no" or "not sure," the anti-pattern is present. | Un-auditable claims; weak footing with customers/regulators. | Separate generation from evidence: log inputs/sources; add deterministic checks; require named human sign-off. |
| Humans as a mop | "We'll just have a human check it" feels safe; verification capacity is never budgeted. | Compare creation throughput vs. verified throughput for the workflow. If creation > verification capacity, you're here. | Reviewer burnout, rubber-stamping, latent defects escaping. | Build a verification pipeline: auto-check what's checkable, route by risk tier, and give reviewers stop-the-line authority. |
A Simple Map (decide if you can scale)
Start here to orient any AI project—define the decision, the risk tier, and then match to the verification capacity required before you scale.
If you can't name how output will be verified (by whom, with what evidence, and at what throughput), you're not ready to grow it.
| Decision context | Primary trust anchor | Evidence source (immutable) | Deterministic checks | Human role | Escalation path |
|---|---|---|---|---|---|
| Low-risk automation (notifications, summaries) | Policy engine + logs | Internal knowledge store with content hashes | Input sanitization, scope limits, content policy checks | None by default; spot audits | Auto-quarantine anomalies to ops queue |
| Medium-risk augmentation (drafts, recommendations) | Verification service + retrieval manifest | Read-only data marts, market snapshots, case repositories | Pointer validation, constraint checks, confidence thresholds | Reviewer signs off or requests refinement | Review ladder to domain owner on yellow flags |
| High-risk adjudication (legal filings, financial moves, clinical actions) | Human adjudicator + control gates | Regulated sources (statutes, filings, formularies) with audit proofs | Dual control, segregation of duties, negative-treatment checks | Mandatory sign-off with rationale | Multi-party approval; policy board on exceptions |
A Checklist for Trust by Design (not by hope)
Wire trust into the workflow—outside the model, with visible provenance and accountable sign-off. Check every box before you scale; if one stays blank, raise verification capacity first.
Evidence over assertion.
| Question | Yes/No Notes |
|---|---|
| Does the system use pointers to immutable evidence instead of model-authored excerpts? | |
| Are deterministic validators (non-AI software systems) checking structure, scope, and support before humans see results? | |
| Can we show a retrieval manifest and reasoning map reconstructed from pipelines, not narratives, for each AI decision and action? | |
| Are alignment constraints enforced at input (sanitizers), process (tools/policies), and output (gates)? | |
| Are roles defined within the new AI system for operators, reviewers, adjudicators, and owners — with clear handoffs? | |
| Is there a review ladder tied to AI decision risk, with dual control where appropriate? | |
| Do we have any mechanism for drift monitoring and an escalation when AI behavior or inputs start to shift? | |
| Can a customer/regulator retrace an output to its evidence, policies, and approvals — fast? | |
| If the model vanished, could we still verify yesterday's decisions from logs and pointers alone? |
If you struggle to check these boxes, the problem isn't that you haven't trained your model well. It's the absence of a system that ensures your model's outputs can deserve trust.
Closing: Vigilant Optimism
We don't need to trust a model like we trust a seasoned professional — and we shouldn't. Models are powerful accelerators, but they're also permeable to poisoned data, prompt injection, and ordinary uncertainty. That isn't a reason to retreat; it's a reason to reallocate trust.
As we've established, when creation became free, trust became the product. The enterprise's value is no longer the artifact itself — it's the validation and trust capital you attach to that artifact: visible provenance, deterministic checks, and accountable humans.
This is why verification capacity sets the ceiling on value. If you scale generation faster than you can prove the work, you print "AI slop" and discount your own outputs to near zero. If you scale verification first — engineering evidence capture, risk-tiered reviews, and named sign-off — you turn speed into credibility. Executives see where risk lives and how it's contained. Regulators see how decisions were made. Customers see why outcomes can be believed. And teams stop redoing machine output and return to what only they can do: apply judgment where it moves the business.
Enterprises that internalize this will not just avoid embarrassment; they'll compound trust. Treat verification as a product you design and a capacity you manage. Price it. Measure it. Make it legible. That is the modern moat — the reason your firm exists in a world where anyone can generate anything.
From here, we build the machinery: the Architecture of Control, the Accountability Layer, and the Decision-Risk Tiers that turn "trust" from marketing language into an operational property of your system. That's how we make AI not merely impressive, but dependable — especially when it's under pressure.